過去にQiitaに投稿した内容のアーカイブです。
Quarkus(https://quarkus.io/) とはSUPERSONIC SUBATOMIC JAVAで、
A Kubernetes Native Java stack tailored for OpenJDK HotSpot and GraalVM, crafted from the best of breed Java libraries and standards.
だそうです。 何言ってるかわかりませんがすごそうです。
GraalVMの機能でJavaのプログラムをネイティブに変換することが可能なので、AWS Lambdaのカスタムランタイムと組み合わせることで AWS Lambda上で動作するJavaアプリケーションの特性である コールドスタートが遅い問題 の解決に期待ができます。
公式サイトの手順に従い試してみましたので、手順を残します。
QUARKUS - BUILDING A NATIVE EXECUTABLE https://quarkus.io/guides/building-native-image
QUARKUS - AMAZON LAMBDA https://quarkus.io/guides/amazon-lambda
環境
- Docker Desktop (Mac) 2.3.0.4
- VSCode + Visual Studio Code Remote - Containers extension
- Amazon Linux 2 (on Docker)
雛形アプリのデプロイ手順
手順1. Amazon Linux 2の環境設定
DockerイメージのAmazon Linux 2はtarやunzipができないので色々入れておきます。
全部必要かわからないですが、これぐらい入れておきました。
yum install -y sudo shadow-utils procps tar.x86_64 gzip xz unzip witch git python3 tree
手順2. GraalVMのインストール
公式サイトからダウンロードして展開します。
curl -s -L -o /tmp/graalvm-ce-java11-linux-amd64-20.1.0.tar.gz https://github.com/graalvm/graalvm-ce-builds/releases/download/vm-20.1.0/graalvm-ce-java11-linux-amd64-20.1.0.tar.gz
tar zxf /tmp/graalvm-ce-java11-linux-amd64-20.1.0.tar.gz -C /opt/
ln -s /opt/graalvm-ce-java11-20.1.0 /opt/graalvm
JAVA_HOMEをGraalVMにして、MavenでのビルドにGraalVMを使用します。
export GRAALVM_HOME=/opt/graalvm
export JAVA_HOME=$GRAALVM_HOME
export PATH=$GRAALVM_HOME/bin:$PATH
最後にNativeビルド時に必要なnative-imageをインストールします。コマンドはgu(GraalVM Updater)です。
gu install native-image
手順3. Mavenのインストール
Quarkusのビルドで使用するMavenは3.6.2以上のバージョンが必要です。yumでインストールできるバージョンが古かったので、公式サイトからダウンロードしてインストールしました。
curl -s -L -o /tmp/apache-maven-3.6.3-bin.tar.gz https://downloads.apache.org/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
tar zxf /tmp/apache-maven-3.6.3-bin.tar.gz -C /opt/
ln -s /opt/apache-maven-3.6.3 /opt/apache-maven
mvnのバージョン確認
bash-4.2# mvn --version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /opt/apache-maven
Java version: 11.0.7, vendor: GraalVM Community, runtime: /opt/graalvm-ce-java11-20.1.0
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.19.76-linuxkit", arch: "amd64", family: "unix"
bash-4.2#
GraalVMのJVMで動作していることがわかります。
手順4. Mavenでプロジェクト作成
mvnコマンドでプロジェクトを生成します。
mvn archetype:generate \
-DarchetypeGroupId=io.quarkus \
-DarchetypeArtifactId=quarkus-amazon-lambda-archetype \
-DarchetypeVersion=1.6.0.Final
しばらくするとプロンプトで質問されますので答えます。 []で囲んだ部分がユーザー入力です。
Define value for property 'groupId': [myGroup]
Define value for property 'artifactId': [myArtifact]
Define value for property 'version' 1.0-SNAPSHOT: : []
Define value for property 'package' myGroup: : [example]
Confirm properties configuration:
groupId: myGroup
artifactId: myArtifact
version: 1.0-SNAPSHOT
package: example
Y: : [Y]
artifactId(myArtifact)でディレクトリが作成され、プロジェクトが生成されます。
作成直後のプロジェクト構成はこんな感じ。
bash-4.2# tree myArtifact/
myArtifact/
├── build.gradle
├── gradle.properties
├── payload.json
├── pom.xml
├── settings.gradle
└── src
├── main
│ ├── java
│ │ └── example
│ │ ├── InputObject.java
│ │ ├── OutputObject.java
│ │ ├── ProcessingService.java
│ │ ├── StreamLambda.java
│ │ ├── TestLambda.java
│ │ └── UnusedLambda.java
│ └── resources
│ └── application.properties
└── test
├── java
│ └── example
│ └── LambdaHandlerTest.java
└── resources
└── application.properties
9 directories, 14 files
bash-4.2#
手順5. Lambdaで起動するHandlerの設定
Lambdaで呼び出されるHandlerはresources/application.propertiesのquarkus.lambda.handlerにて設定します。
quarkus.lambda.handler=test
上記設定の場合は、以下のtestと名前をつけたクラスが呼び出されます。
@Named("test")
public class TestLambda implements RequestHandler<InputObject, OutputObject> {
}
あとは通常のLambdaと同様にコーディングします。
雛形にはtestの他にstreamなども用意されています。
手順6. デプロイパッケージの作成
一旦雛形のままデプロイパッケージを作成してみます。
mvn clean package -Pnative
めちゃくちゃ時間がかかります。10分以上かかると思います。
手順7. デプロイパッケージの内容の確認
無事デプロイパッケージができると、target/function.zipが生成されいます。試しに展開してみると、中身はbootstrapのみでした。
bash-4.2# unzip function.zip
Archive: function.zip
inflating: bootstrap
bash-4.2#
手順8. Lambdaのデプロイ
targetディレクトリ内には、manage.shというファイルも生成されており、ここからAWS上にデプロイしたりできるようです。
私はカスタムランタイムが初めてだったこともあり、マネジメントコンソールから試してみました。
デプロイパッケージ作成後に、target/sam.native.yamlというファイルも生成されるので、ハンドラー名や環境変数はこちらを参考にしました。
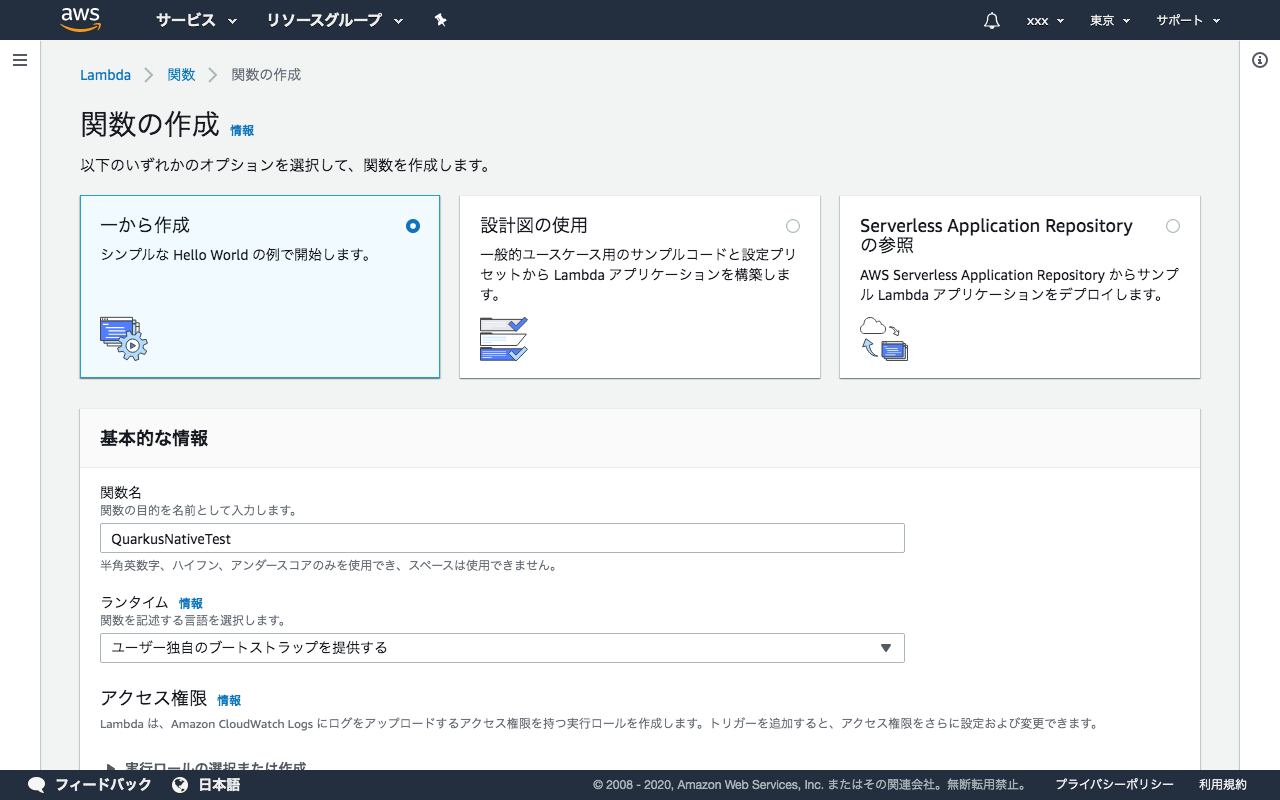
関数を新規作成します。
ランタイムをユーザー独自のブートストラップを提供するとします。
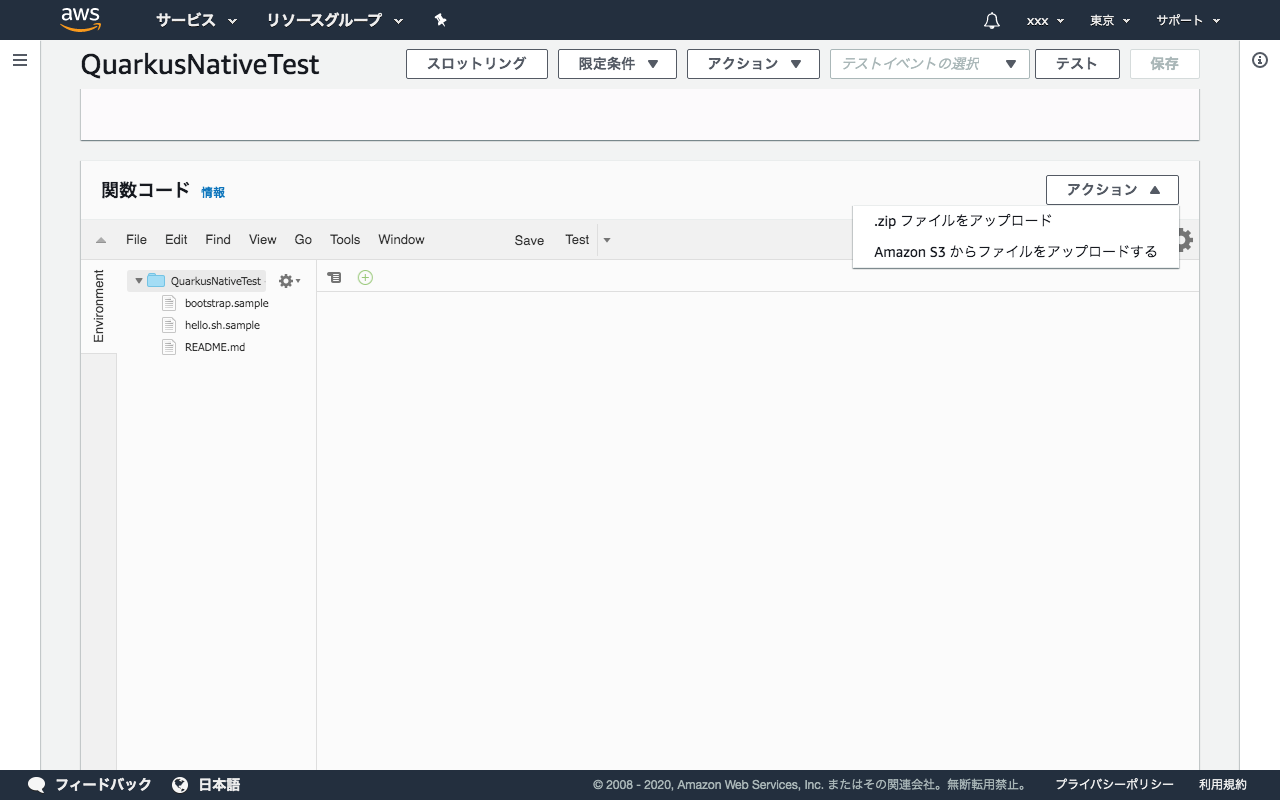
関数を作成したら、プログラムをアップロードします。
関数コードのところのアクションから.zipファイルをアップロードを選び、function.zipを選択します。
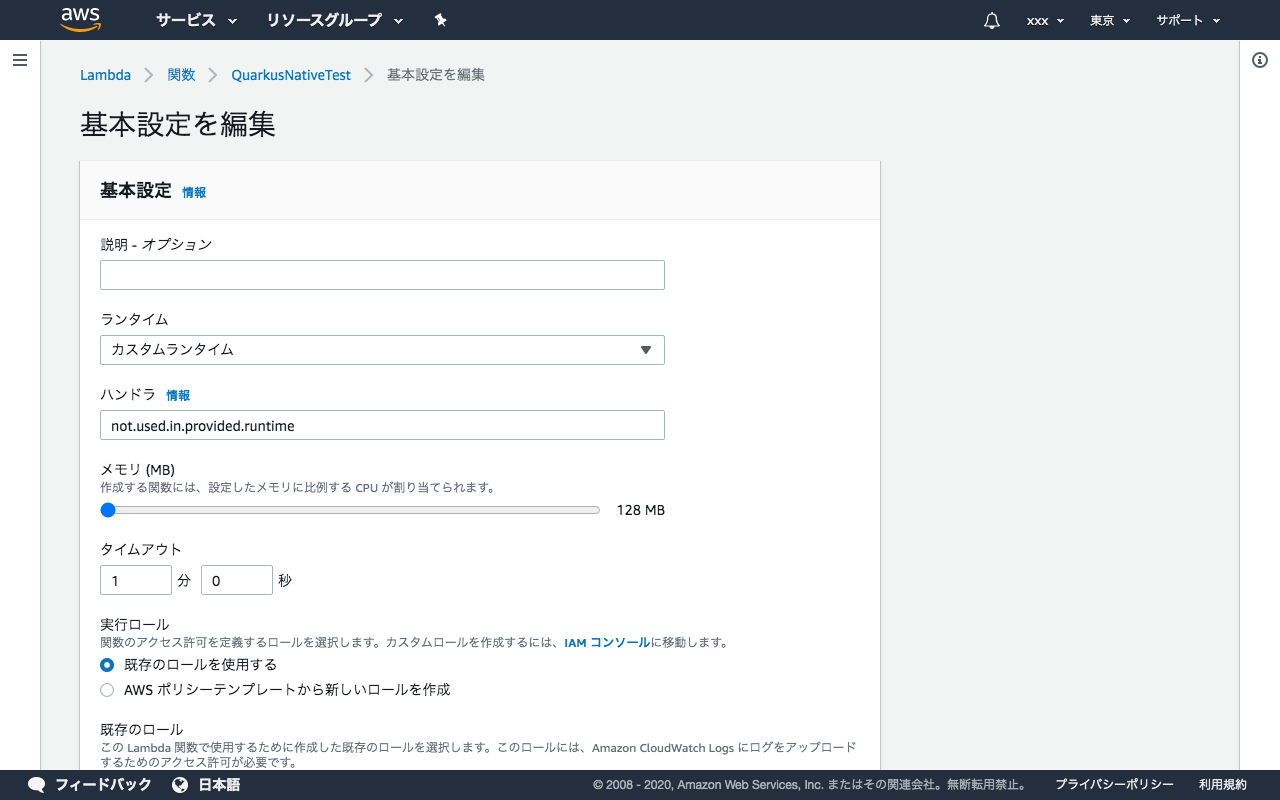
ハンドラーはnot.used.in.provided.runtimeとなります。
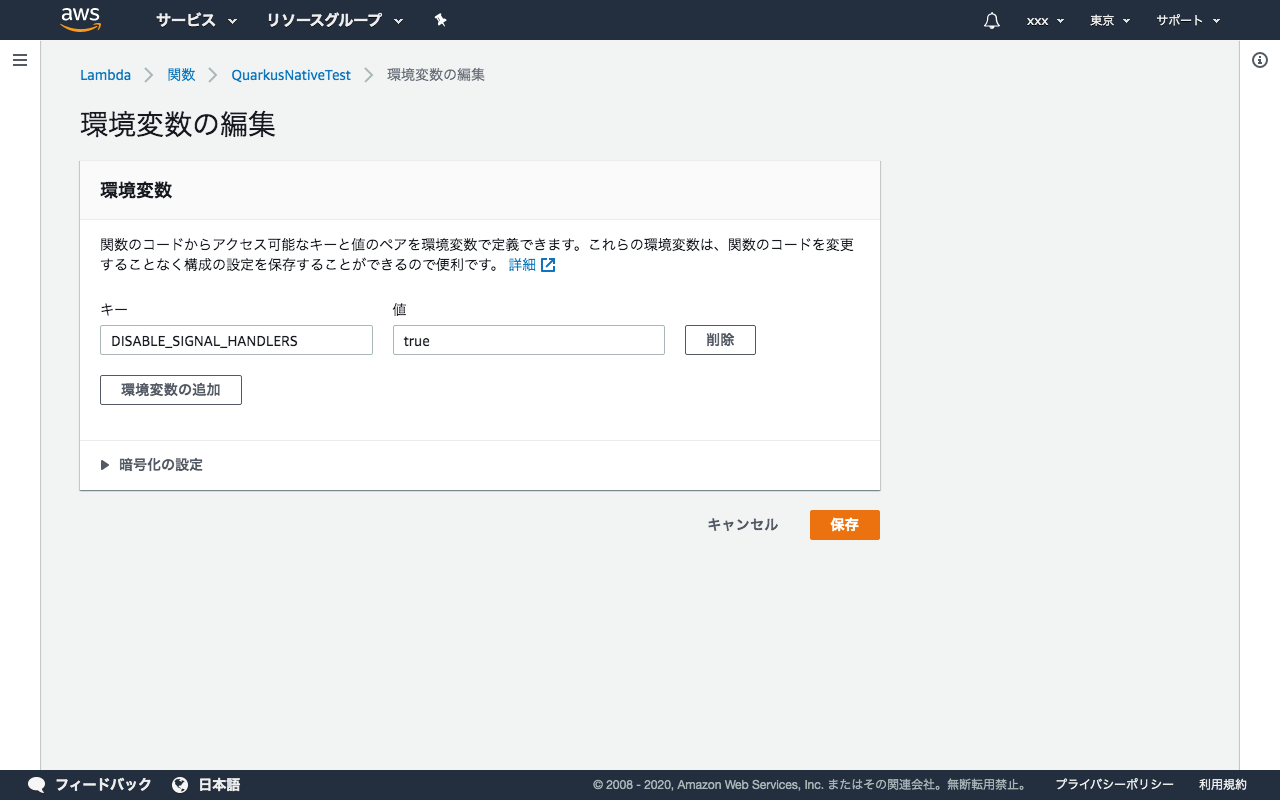
環境変数にDISABLE_SIGNAL_HANDLERSを追加し値をtrueとします。
ここまでで設定は完了です。以下のJSONをインプットにテスト実行してみましょう。
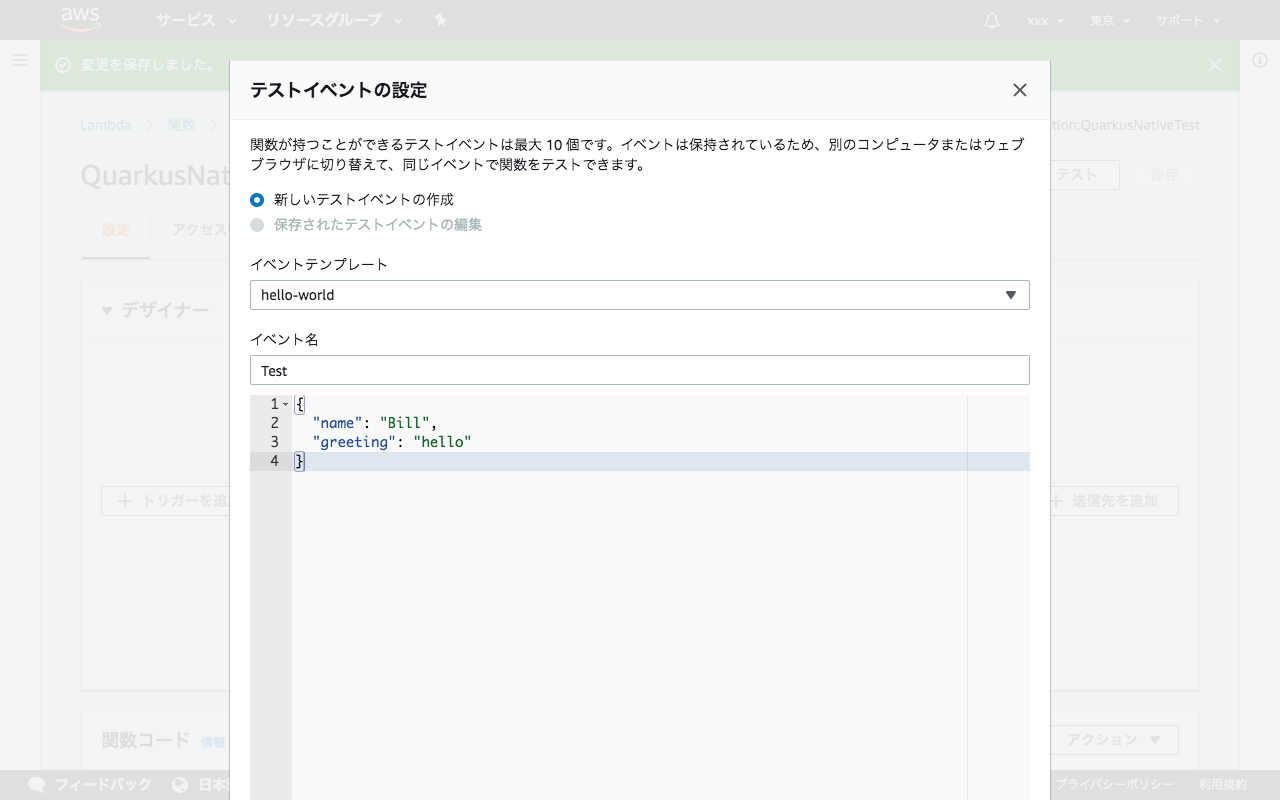
{
"name": "Bill",
"greeting": "hello"
}
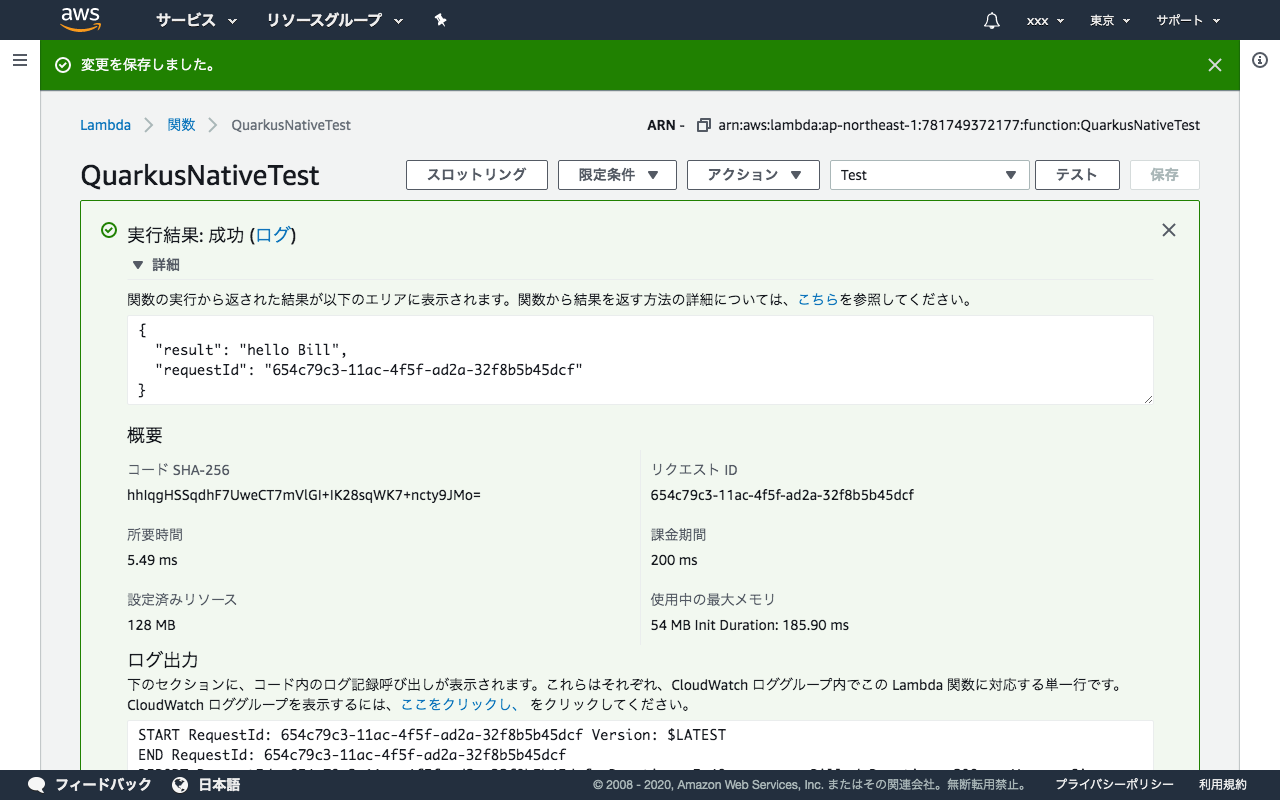
動作結果がこちら。無事動きました。
AWS SDK を追加
AWS SDKを使用するには単純にpom.xmlに追加するだけでなく、いくつか設定が必要です。
手順1. SSL通信の有効化
resources/application.propertiesに以下の内容を追加します。(公式ドキュメント的にはデフォルトで有効って書いてある気もしますが)
quarkus.ssl.native=true
手順2. 依存関係の追加
まずは、quarkus-jaxbが必要とのことで、これを追加します。
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jaxb</artifactId>
</dependency>
次にAWS SDKのライブラリーを追加するのですが、
For native image, however the URL Connection client must be preferred over the Apache HTTP Client when using synchronous mode, due to issues in the GraalVM compilation (at present).
翻訳すると
ただし、ネイティブイメージの場合、GraalVMコンパイルの問題(現在)のため、同期モードを使用するときは、Apache HTTPクライアントよりもURL接続クライアントを優先する必要があります。
だそうです。そのため、以下のような記述となります。
<properties>
<aws.sdk2.version>2.10.69</aws.sdk2.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>${aws.sdk2.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>url-connection-client</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
<exclusions>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<exclusions>
<!-- exclude the apache-client and netty client -->
<exclusion>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
</exclusion>
<exclusion>
<groupId>software.amazon.awssdk</groupId>
<artifactId>netty-nio-client</artifactId>
</exclusion>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>commons-logging-jboss-logging</artifactId>
<version>1.0.0.Final</version>
</dependency>
</dependencies>
手順3. Javaコードの作成
S3にアクセスする例ですが、S3Clientを生成する際に、httpClientにて明示的にUrlConnectionHttpClientを指定します。
S3Client s3 = S3Client.builder()
.region(Region.AP_NORTHEAST_1)
.httpClient(software.amazon.awssdk.http.urlconnection.UrlConnectionHttpClient.builder().build())
.build();
手順4. SSL通信に必要な設定
SSL通信を行うためにデプロイパッケージに以下を含める必要があります。
- カスタムBootstrap
- libsunec.so
- cacerts
まず、src/main/zip.native/ディレクトリを作成し、bootstrapを作成します。
#!/usr/bin/env bash
./runner -Djava.library.path=./ -Djavax.net.ssl.trustStore=./cacerts
次にlibsunec.soとcacertsをコピーします。この2つのファイルはGraalVMに含まれています。
cp $GRAALVM_HOME/lib/libsunec.so $PROJECT_DIR/src/main/zip.native/
cp $GRAALVM_HOME/lib/security/cacerts $PROJECT_DIR/src/main/zip.native/
手順5. デプロイパッケージの作成
デプロイパッケージの作成手順は変わりません。
mvn clean package -Pnative
手順6. デプロイパッケージの内容の確認
SSL有効化した状態でデプロイパッケージを作成すると、target/function.zipの中身が変わります。
bash-4.2# unzip function.zip
Archive: function.zip
inflating: bootstrap
inflating: cacerts
inflating: libsunec.so
inflating: runner
bash-4.2#
事前準備したbootstrap``cacerts``libsunec.soが含まれているのがわかります。
終わりに
通常のJavaランタイムよりも、コールドスタートが早くなる検証結果はこちらで確認ください。