Scratchに代表されるブロックプログラミング形式でAWSにアクセスするものを作ってみました。
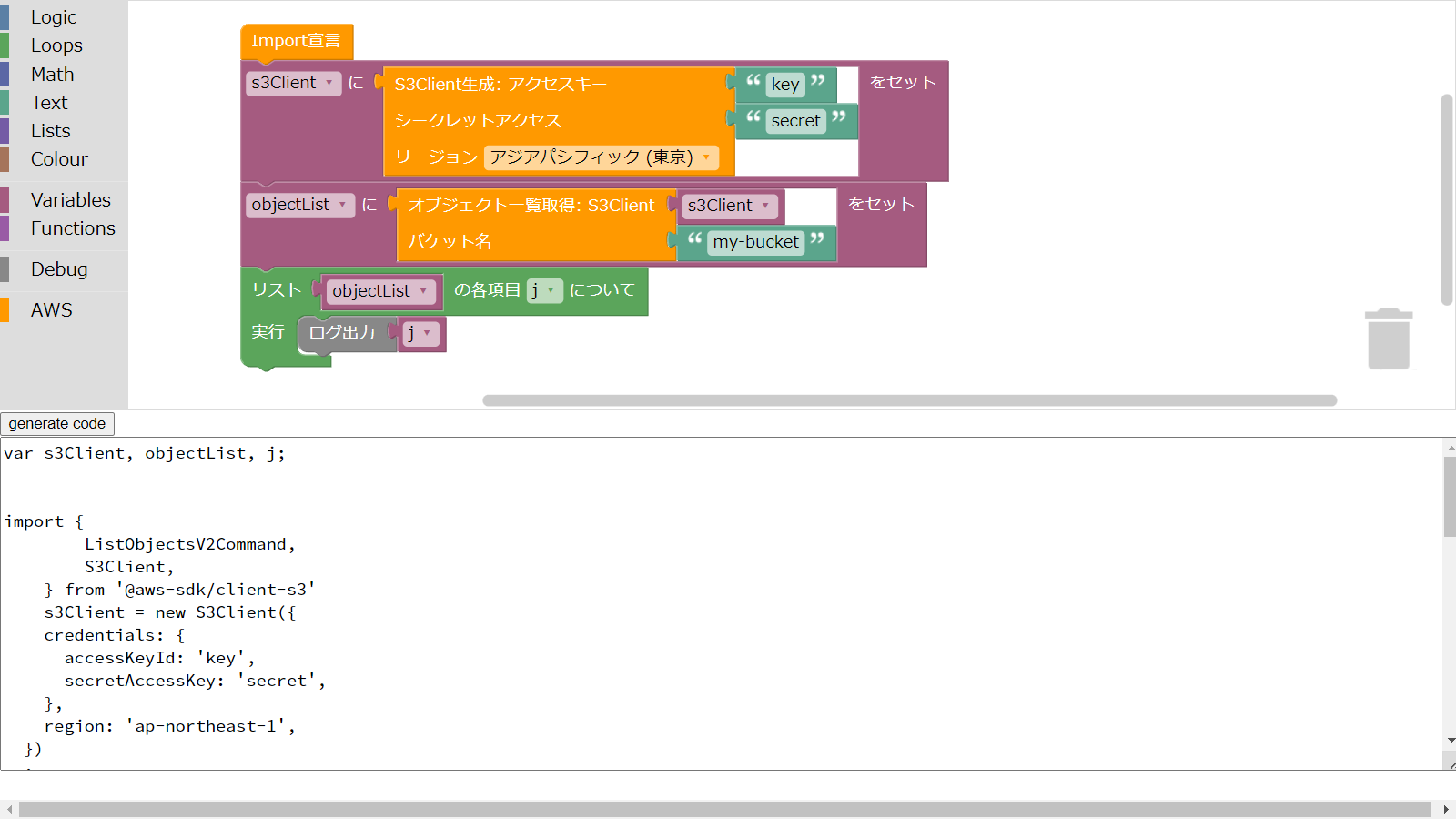
Scratchに代表されるブロックプログラミング形式でAWSにアクセスするものを作ってみました。
Security Hubでチェックができるセキュリティ基準は以下の3つがあります。
セキュリティは大事です。AWSのセキュリティ状況を把握するSecurity Hubというサービスの利用方法を紹介します。
過去にQiitaに投稿した内容のアーカイブです。
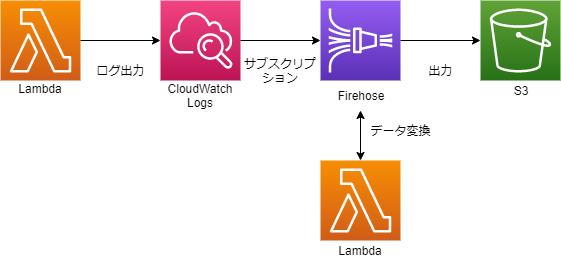
CloudWatch Logsに出力されたLambdaのログをS3に保管する方法です。
CloudWatch Logsのサブスクリプションという機能でログをKinesis Data Firehoseに送信します。 そのままS3に出力すると複数のログが1行に並ぶ形になってしまいますが、Kinesis Data Firehoseのデータ変換機能で改行を加えることで解決します。
こんな感じです。
ログを出力するバケットを作成します。今回はlog-backup-xxxxxとします。
データ変換用LambdaはAWSが設計図を用意してくれているので簡単に作成できます。 マネジメントコンソールでLambda関数を作成します。
| 項目 | 選択 | 説明 |
|---|---|---|
| 作成方法 | 設計図の使用 | |
| 設計図 | kinesis-firehose-cloudwatch-logs-processor | Node.js版。Python2.7版のkinesis-firehose-cloudwatch-logs-processor-pythonもあります |
| 関数名 | kinesis-firehose-cloudwatch-logs-processor | 任意 |
| 実行ロール | 基本的なLambdaアクセス権限で新しいロールを作成する |
ソース中にコメントに以下の記載があり、どのような形式のログが渡ってくるかがわかります。
/*
For processing data sent to Firehose by Cloudwatch Logs subscription filters.
Cloudwatch Logs sends to Firehose records that look like this:
{
"messageType": "DATA_MESSAGE",
"owner": "123456789012",
"logGroup": "log_group_name",
"logStream": "log_stream_name",
"subscriptionFilters": [
"subscription_filter_name"
],
"logEvents": [
{
"id": "01234567890123456789012345678901234567890123456789012345",
"timestamp": 1510109208016,
"message": "log message 1"
},
{
"id": "01234567890123456789012345678901234567890123456789012345",
"timestamp": 1510109208017,
"message": "log message 2"
}
...
]
}
The data is additionally compressed with GZIP.
The code below will:
1) Gunzip the data
2) Parse the json
3) Set the result to ProcessingFailed for any record whose messageType is not DATA_MESSAGE, thus redirecting them to the
processing error output. Such records do not contain any log events. You can modify the code to set the result to
Dropped instead to get rid of these records completely.
4) For records whose messageType is DATA_MESSAGE, extract the individual log events from the logEvents field, and pass
each one to the transformLogEvent method. You can modify the transformLogEvent method to perform custom
transformations on the log events.
5) Concatenate the result from (4) together and set the result as the data of the record returned to Firehose. Note that
this step will not add any delimiters. Delimiters should be appended by the logic within the transformLogEvent
method.
6) Any additional records which exceed 6MB will be re-ingested back into Firehose.
*/
処理手順も色々ありそうですが、そのあたりはすでに実装済みなので、変換する形式を変更したい場合はtransformLogEvent関数を修正するだけです。
設計図での実装は、付加情報は全部除外して、ログのメッセージに改行を付与して出力しています。
/**
* logEvent has this format:
*
* {
* "id": "01234567890123456789012345678901234567890123456789012345",
* "timestamp": 1510109208016,
* "message": "log message 1"
* }
*
* The default implementation below just extracts the message and appends a newline to it.
*
* The result must be returned in a Promise.
*/
function transformLogEvent(logEvent) {
return Promise.resolve(`${logEvent.message}\n`);
}
例えば、logEventの内容をすべて出力し改行を付与する場合は、以下の様になると思います。
function transformLogEvent(logEvent) {
return Promise.resolve(`${JSON.stringify(logEvent)}\n`);
}
また、Amazon Kinesis Data Firehose CloudWatch Logs Processorというテストイベントも用意されているので、マネジメントコンソールで簡単にテストができます。
最後に、Lambdaのタイムアウトを1分以上にしておきましょう。
マネジメントコンソールで作成します。
| 項目 | 選択 | 説明 |
|---|---|---|
| Delivery stream name | CloudWatchLogs-to-S3 | 任意 |
| Choose a source | ||
| source | Direct PUT or other sources | |
| ---次のページ--- | ||
| Transform source records with AWS Lambda | ||
| Record transformation | Enabled | |
| Lambda function | kinesis-firehose-cloudwatch-logs-processor | 作成したLambda |
| Lambda function version | $LATEST | |
| Convert record format | ||
| Record format conversion | Disabled | |
| ---次のページ--- | ||
| Select a destination | ||
| Destination | Amazon S3 | |
| S3 destination | ||
| S3 destination | log-backup-xxxxx | 作成したバケット |
| S3 prefix | logs/ | |
| S3 error prefix | error/ | |
| S3 backup | ||
| Source record S3 backup | Disabled | |
| S3 buffer conditions | ||
| Buffer size | 5MB | デフォルト値 |
| Buffer interval | 300seconds | デフォルト値 |
| S3 compression and encryption | ||
| S3 compression | Disabled | |
| S3 encryption | Disabled | |
| Error logging | ||
| Error logging | Enabled | |
| Permissions | ||
| IAM role | Create new or choose | 新しくIAMロールを作成するといい感じにアクセス権限を付与してくれます |
このあとの手順で作成するCloudWatch Logsのサブスクリプションフィルターに、Firehoseにアクセスする権限が必要なので、IAMロールを作成します。 ただ、マネジメントコンソール上からは、CloudWatch Logsに付与するIAMロールはそのままでは作れないので、以下の手順で作成します。
まずはマネジメントコンソールでIAMロールを作成します。
| 項目 | 選択 | 説明 |
|---|---|---|
| 信頼されたエンティティの種類を選択 | AWSサービス | |
| このロールを使用するサービスを選択 | EC2 | |
| Attach アクセス権限ポリシー | なし | 次の手順で付与します |
| ロール名 | CWLtoKinesisFirehoseRole | |
| ロールの説明 | 削除 | 説明がEC2になってるので削除しておく |
次にIAMポリシーを作成します。
| 項目 | 選択 | 説明 |
|---|---|---|
| サービス1 | ||
| サービス | Firehose | |
| アクション | すべてのFirehoseアクション | |
| リソース | arn:aws:firehose:ap-northeast-1:[アカウントID]:deliverystream/CloudWatchLogs-to-S3 | 作成したFirehoseの配信ストリームのARN |
| サービス2 | ||
| サービス | IAM | |
| アクション | PassRole | |
| リソース | arn:aws:iam::[アカウントID]:role/CWLtoKinesisFirehoseRole | 作成したIAMロールのARN |
| ---次のページ--- |
| ポリシーの確認 | 名前 | Permissions-Policy-For-CWL |
再度IAMロールの編集画面に戻り、CWLtoKinesisFirehoseRoleロールにPermissions-Policy-For-CWLポリシーをアタッチします。
最後にCWLtoKinesisFirehoseRoleロールの信頼関係タブの信頼関係の編集をクリック。"Service": "ec2.amazonaws.com"の部分を"Service": "logs.ap-northeast-1.amazonaws.com"に変更し、保存します。
マネジメントコンソールからは作成できないようですので、CLIで作成します。
| パラメータ(キー) | パラメータ(値) | 説明 |
|---|---|---|
| --log-group-name | /aws/lambda/xxxxxx | サブスクリプションフィルターを追加したいロググループ名 |
| --filter-name | Logs-to-Firehose | 任意 |
| --filter-pattern | "" | フィルターせず、全ての場合 |
| --destination-arn | arn:aws:firehose:ap-northeast-1:[アカウントID]:deliverystream/CloudWatchLogs-to-S3 | 作成したFirehoseの配信ストリームのARN |
| --role-arn | arn:aws:iam::[アカウントID]:role/CWLtoKinesisFirehoseRole | 作成したIAMロールのARN |
aws logs put-subscription-filter --log-group-name [ロググループ名] --filter-name Logs-to-Firehose --filter-pattern "" --destination-arn arn:aws:firehose:ap-northeast-1:[アカウントID]:deliverystream/CloudWatchLogs-to-S3 --role-arn arn:aws:iam::[アカウントID]:role/CWLtoKinesisFirehoseRole
これで無事にS3にCloudWatchLogsがS3に保存されます。 GlueやAthenaでもクエリーがかけられそうです。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/SubscriptionFilters.html#FirehoseExample https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/data-transformation.html https://docs.aws.amazon.com/cli/latest/reference/logs/put-subscription-filter.html
過去にQiitaに投稿した内容のアーカイブです。
簡単なPythonプログラムをFargateで実行するまでの道のりです。
import os
import boto3
bucket = os.getenv('BUCKET_NAME', '')
key = 'HelloWorld.txt'
body = 'Hello, World!'
s3 = boto3.client('s3')
s3.put_object(Bucket=bucket, Key=key, Body=body)
環境変数で渡したバケットに固定文字列のファイルを出力するだけです。
試した環境は
7/7 更新 S3エンドポイントは不要でしたので記述を削除しました。
python -m venv .venv
.venv\Scripts\activate
pip install boto3 awscli
aws configure
AWS Access Key ID [None]: [アクセスキー]
AWS Secret Access Key [None]: [シークレットアクセスキー]
Default region name [None]: [ap-northeast-1などのリージョン]
Default output format [None]:
バケット名は環境変数から取得するようにしたので、環境変数にバケット名をセットします
set BUCKET_NAME=[バケット名]
python -m app
無事、S3にファイルが出力されました。
requirements.txtとDockerfileを用意し、app.pyと同じフォルダーに格納します。
boto3==1.9.183
FROM python:alpine
WORKDIR /app
ADD . /app
RUN python3 -m pip install -r requirements.txt
CMD ["python3", "-m", "app"]
docker build -t [Dockerイメージのタグ名] .
コンテナ内にはAWSの認証情報がないので、環境変数で渡します。バケット名も同様です。
docker run -e AWS_ACCESS_KEY_ID=[アクセスキー] -e AWS_SECRET_ACCESS_KEY=[シークレットアクセスキー] -e BUCKET_NAME=[バケット名] [Dockerイメージのタグ名]
無事、S3にファイルが出力されました。
Fargateで実行するため、DockerイメージをECR(Elastic Container Registry)に登録します。
aws ecr create-repository --repository-name [リポジトリ名]
aws ecr get-login --no-include-email
コンソールに出力されるコマンドを実行します。
docker image tag [ローカルのDockerイメージのタグ名] [リポジトリ名]:[リモートのDockerイメージ名]
docker image push [リポジトリ名]:[リモートのDockerイメージ名]
マネジメントコンソールでECSの画面を表示。クラスターを作成する。
| 設定項目 | 設定内容 |
|---|---|
| クラスターテンプレートの選択 | ネットワーキングのみ |
| クラスターの設定 | このクラスター用の新しいVPCを作る |
マネジメントコンソールでECSの画面を表示。タスク定義を作成する。
| 設定項目 | 設定内容 |
|---|---|
| 起動タイプの互換性の選択 | FARGATE |
| タスクとコンテナの定義の設定 | ↓↓↓ |
| タスク実行ロール | AmazonECSTaskExecutionRolePolicyの他にS3へのPutObject権限も必要 |
| コンテナの定義 | ↓↓↓ |
| イメージ | ECRのイメージ URI(マネジメントコンソールで確認する) |
| 環境変数 | BUCKET_NAMEにバケット名を指定 |
タスク定義から作成したものを選び、アクションのタスクの実行を行います。
| 設定項目 | 設定内容 |
|---|---|
| 起動タイプ | FARGATE |
| クラスター | 作成したもの |
| タスクの数 | 1 |
| VPC | 作成したもの |
ウィザードの最後のタスクの実行を押すと、実行されます。
クラスターから作成したものを選び、画面下のタブにあるタスクのスケジューリングの先の作成を選びます。
| 設定項目 | 設定内容 |
|---|---|
| スケジュールルールタイプ | お好みで |
| 起動タイプ | FARGATE |
| タスク定義 | 作成したもの |
| タスクの数 | 1 |
| クラスター VPC | 作成したもの |
ウィザードの最後の作成を押すと、指定したスケジュールに従って実行されます。
固定された間隔で実行の場合、初回起動は作成を押してから固定された間隔が経過したあとになるようです。
後半がかなり手抜きになりましたが、一応Fargateで動作するところまでできました。